
Building a Powerful AI Application: Complementary to Architectural Planning
Runtime Environment and Backend Non-Functional Requirements

Mistaken ideas about software architecture sometimes arise, typically from those without years of hands-on experience. While previous articles touch on architectural concepts, they rarely go deeply or offer concrete examples. Often, managers and other non-technical professionals can imagine general aspects of architecture at an abstract level, drawing on technical summaries. However, truly understanding complex technical systems requires direct experience—much like a firefighter intimately familiar with water pressure dynamics during a critical moment, or a racecar driver who can feel the nuanced difference in tire performance when pressure varies under high-speed conditions in a turn. Both instances reflect how subtle, practical knowledge shapes the understanding of systems in ways theory alone cannot.
When asked, 'What is the best system or software architecture?' it often signals either a test of the responder’s expertise or that the person asking may not fully understand architecture. The question is akin to asking, 'What’s the best architectural design for a building?' without specifics. To truly answer, one must know the where, what, why, who, and when. Consider if the project is a bridge over desert sands or an extension to a museum in a freezing climate. Similarly, designing a small dinghy versus a container ship involves entirely different requirements, resources, components, and regulations, even though both are watercraft.
Software architecture parallels these physical examples: it’s the optimal arrangement of components, systems, and integrations to meet the specific requirements of the project. Even when starting from scratch, a software architecture will often integrate or coexist with other systems, each with its own architecture. Additionally, most software is built on top of, or within, other architectural layers that influence design choices. So, just as with physical architecture, there is no universal 'best'—only the best fit for the given situation.
In a previous article, we presented a diagram illustrating a potential system architecture built in the AWS cloud. AWS provides an N-Tier infrastructure, which means it is organized in multiple layers that separate concerns and simplify scaling. AWS offers a wide array of ready-made services and products that can be used as building blocks. These components must be configured and interconnected to work as a cohesive system. For instance, an EC2 server running a Unix-based operating system might interact with database instances like Oracle or Redis to handle data.
While the cloud itself follows an N-Tier structure, additional architectural patterns can be layered on top of it. For example, a Service-Oriented Architecture (SOA)—a component-based architecture—can be implemented within this environment. Various architectural patterns are available for system design, each created to solve specific recurring challenges. Some commonly used patterns include Pipes and Filters, Blackboard, Model-View-Controller (MVC), and Microservices. Selecting the right pattern depends on the specific requirements and goals of the application.
The choice of architecture for a system depends on what we aim to accomplish with it and the specific nature of the system itself. This decision-making process is similar to selecting the appropriate tools and materials based on the project type. For instance, when constructing a new village, we would use trucks to transport sand and rubble, not milk. When building a bunker, we would need substantial metal reinforcement before pouring in cement. Although both examples involve construction, the methods and materials vary widely due to their different requirements.
In technology, architecture is tailored similarly. If our goal is to broadcast traffic alerts that cars can pick up like a radio signal, the architecture would differ significantly from an Online Transaction Processing (OLTP) system, which processes telecommunications packets over the internet. These systems diverge in terms of data volume, target users, and required speed.
To avoid an overly lengthy discussion, I'll highlight a few essential architectural considerations. Afterward, we’ll examine the architecture of a high-availability CRM system based on XAMPP, covering key points without going intointo every aspect. Finally, we’ll look at a cloud-based platform for AI and ML that leverages both local, on-premise components and cloud integrations, with flexibility to use elements beyond AWS.
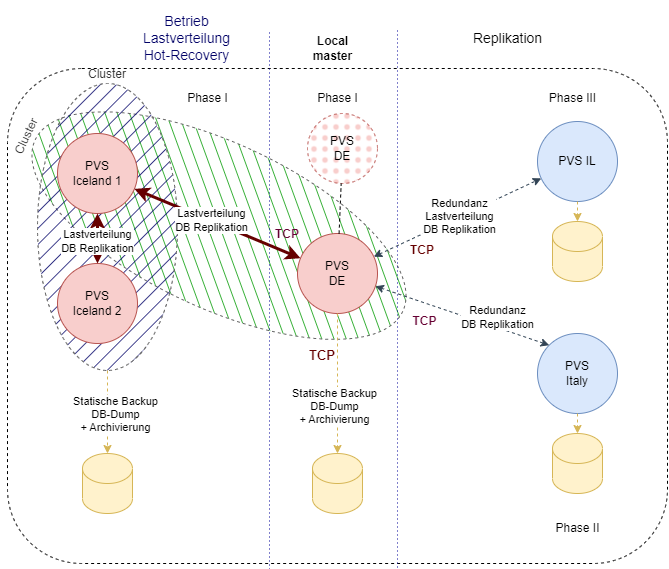
The diagram is in German captions: later in English as well
This architecture is a budget-conscious approach designed to ensure high availability and crash recovery. It’s built on a Unix operating system running an Apache Web Server and MySQL RDBMS.
At its core is a Joomla-based CRM system hosted on a centralized ‘master’ server. This master server is configured for direct user access, while additional ‘slave’ servers handle load balancing. Load balancing is managed via Apache’s software-based configurations, allowing for horizontal scalability as the system expands.
MySQL servers use replication to synchronize data across instances, ensuring data redundancy and reliability. In case of a server failure, this setup minimizes downtime and data loss. Data backups are also automated and stored on independent servers, located in different countries to provide an added layer of security and regulatory compliance.
Users can customize this architecture by examining regulatory requirements, disaster recovery plans, and associated costs, depending on specific organizational needs.
Though this is not a cloud-based architecture and doesn’t utilize proprietary software modules, it meets the requirements for the expected user load, data volume, and network traffic. The system doesn’t demand ultra-low latency or real-time processing, as it primarily serves dynamically generated HTML pages to users without performing on-the-fly calculations.
Extra servers improve resilience, storing backup data and reducing crash recovery time in events like a cyberattack. Automation scripts and a ‘watchdog’ monitoring process enhance system uptime by quickly identifying issues. In case of a failure, the system can restart the Apache daemon programmatically, enabling rapid recovery within seconds due to data replication and the restart of the background Unix process.
What are the so-called non-functional requirements for a high-performance ML and AI machine in the cloud? What are the considerations when building a system that not only recognizes faces but also tracks the figure across a square? Let’s say we have 200-500 surveillance cameras surrounding a major city. Not all of them are monitoring a square, some are focused on traffic, but the system performs the same function: it classifies single frames on demand and logically connects them between frames.
We will continue this discussion soon. We cannot cover all aspects at once, but we will focus on a few aspects each time.
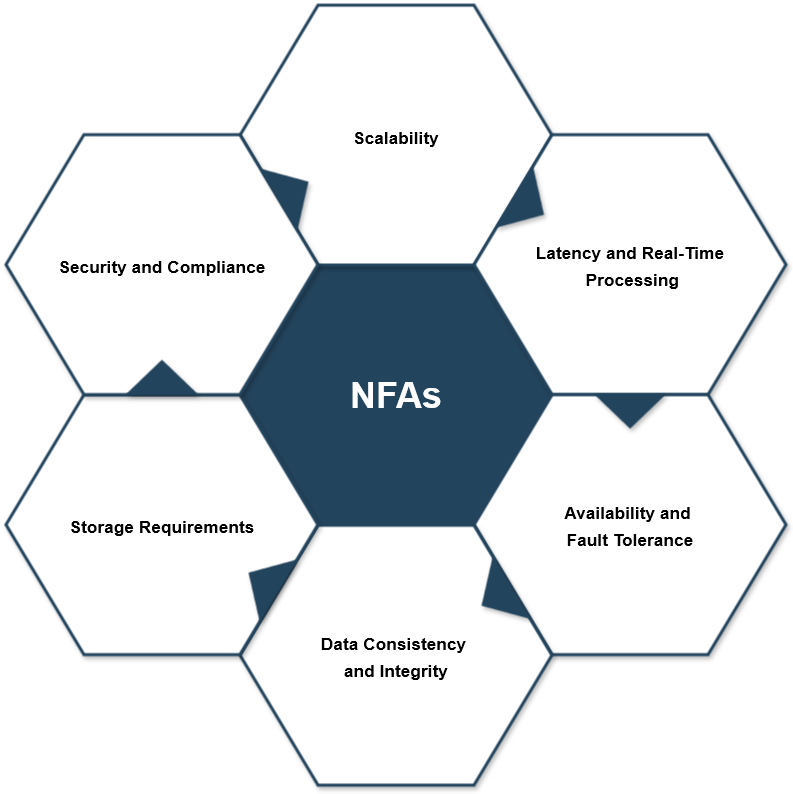
Scalability
To handle an increasing volume of data from more cameras, the system should be able to scale both horizontally and vertically. Horizontal scaling involves adding more machines to distribute workloads, while vertical scaling means upgrading individual machines. This ensures efficient real-time processing, even as the system expands.
Latency and Real-Time Processing
Low latency is crucial for applications like figure tracking, where quick responses are needed. To minimize delays, edge computing can process data closer to the source (e.g., on the cameras themselves) before sending it to the main system for analysis, reducing transmission delays.
Availability and Fault Tolerance
To ensure the system remains operational without interruption, high availability is essential. This can be achieved by implementing redundancy and failover mechanisms, such as using multiple server clusters that take over in case one fails. Real-time services should continue seamlessly even if a component experiences issues.
Data Consistency and Integrity
Maintaining consistent and accurate data is important, but strict real-time consistency isn’t always necessary for all parts of the system. For non-critical data, eventual consistency can be an acceptable model, while real-time processing of crucial information (like tracking movements or sending alerts) should rely on up-to-date data. Proper versioning and validation processes are key for maintaining data integrity across the system.
Storage Requirements
Given the massive amounts of video data generated by the surveillance system, high-capacity and high-throughput storage are necessary. Cloud storage solutions, such as Amazon S3, combined with data lakes or warehouses, can handle the large volume of data efficiently. Clear retention policies for data storage and deletion are important to manage costs and ensure compliance with regulations.
Security and Compliance
Since surveillance footage is highly sensitive, ensuring its security is paramount. The system should implement strong encryption, access control mechanisms, and constant monitoring to prevent unauthorized access. Additionally, it must adhere to data privacy laws, ensuring that data is handled responsibly, with full traceability and accountability.
Glossary
| Term | Definition |
|---|---|
| Software Architecture | The high-level structure of a software system, defining the organization of its components, their interactions, and integration. |
| N-Tier Architecture | A software architecture pattern that organizes a system into multiple layers (e.g., presentation, business logic, data) to separate concerns and enhance scalability. |
| AWS | Amazon Web Services, a cloud computing platform offering various services like compute power, storage, and databases. |
| EC2 | Elastic Compute Cloud, an AWS service that provides resizable compute capacity in the cloud. |
| Unix | A powerful, multi-user, multitasking operating system commonly used for servers. |
| RDBMS | Relational Database Management System, a type of database management system (DBMS) that stores data in a structured format using tables. |
| Oracle | A widely used RDBMS developed by Oracle Corporation. |
| Redis | An open-source, in-memory data structure store, commonly used for caching and real-time applications. |
| SOA (Service-Oriented Architecture) | A software design pattern that structures a system as a collection of services that communicate over a network. |
| Microservices | An architectural style that structures an application as a collection of loosely coupled services, each handling a specific function. |
| Pipes and Filters | An architectural pattern where data flows through a series of processing steps (filters) connected by pipes. |
| Model-View-Controller (MVC) | A software design pattern that separates an application into three main components: the model (data), the view (UI), and the controller (logic). |
| OLTP (Online Transaction Processing) | A class of systems that supports transactional applications, such as processing orders or bank transactions, often involving high-volume data. |
| XAMPP | A free and open-source cross-platform web server solution stack package, consisting of Apache, MySQL, PHP, and Perl. |
| High Availability | A system design approach that ensures a high level of operational performance, uptime, and reliability, often involving redundancy and failover mechanisms. |
| Crash Recovery | The ability of a system to recover from a failure, such as a crash or data corruption, ensuring minimal disruption and data loss. |
| Load Balancing | The distribution of incoming network traffic across multiple servers to ensure efficient resource utilization and availability. |
| Replication | The process of copying and maintaining database objects, such as tables, in multiple locations to ensure data redundancy and high availability. |
| Disaster Recovery Plans | A set of procedures to follow in the event of a system failure, including data recovery and ensuring business continuity. |
| Edge Computing | A distributed computing framework that brings computation and data storage closer to the location where it is needed, reducing latency. |
| Latency | The delay between a user's action and the system’s response, critical in systems that require real-time or near-real-time processing. |
| Fault Tolerance | The ability of a system to continue functioning despite the failure of one or more components. |
| Data Consistency | Ensuring that data remains accurate, reliable, and up-to-date across different parts of the system. |
| Eventual Consistency | A model where data consistency is achieved over time, with the assumption that the system will eventually reach consistency after updates. |
| Cloud Storage | A service that allows users to store data on remote servers accessed via the internet, offering scalability and remote access. |
| Data Privacy Laws | Legal regulations governing how personal data is collected, stored, and shared, ensuring user privacy and security. |
| Encryption | The process of converting data into a code to prevent unauthorized access. |
| Access Control | A security technique that regulates who or what can view or use resources in a computing environment. |