
Building a Powerful AI Application: From Vision to Implementation
Architecting and Building a Robust AI System: Key Considerations for Scalable Design and Implementation

We are setting out to build a powerful AI application, and, of course, defining the subject matter is the first step. What exactly will this application do, and how will it be useful and usable? While this is always a key question when developing any application, there are additional considerations that come with the nature of the project. This is no ordinary application—it will leverage vast amounts of data and incorporate machine learning (ML), all while aiming to provide real-time or near-real-time results.
This makes it a much more complex endeavor, like constructing a sophisticated machine with many moving parts. Each part of the application is essential and needs to work in perfect sync with the others. However, as with any complex system, we can break it down into smaller, manageable components that can be developed separately.
The framework and phases of this machine, while intricate, align with the architecture of any other large-scale application. During this process, we will adhere to best practices while giving extra focus to certain parts—especially those non-functional requirements and specialized logical units—that are more critical in the context of AI and ML-driven applications.
We could have some parts of the system as subsystems or components that are already available or existing within the infrastructure landscape. Since their role is identical, it ultimately becomes a business decision whether to use these existing components or create new ones. However, there may be cases where integrating these existing components is either not feasible or not cost-effective, in which case they will be ruled out. Therefore, we approach the process as if no existing components are available for use.
The Vision
What is the blueprint of the application, and what exactly will it do? Defining this is crucial because it will influence how we select the complexity of algorithms and the data to be used. Will the application handle structured data or document-based data? Is it going to be an automated tool, a recommendation system, or a strategy-driven platform that is event-driven and operates in real-time? These decisions will directly affect the performance requirements and, in many cases, will guide the selection of architecture and technology stack.
The “Factory”
Imagine a factory that produces something unique as the output of the entire production process—much like what the AI application will generate. To achieve this, it requires a vast amount of raw data, which is stored, processed, retrieved, cached, and regenerated to create data marts. Data acts as the lifeblood of the system, flowing through the various machines that prepare it. These machines feed the machine learning models, enabling the AI's logical units to process the data and produce the desired output.
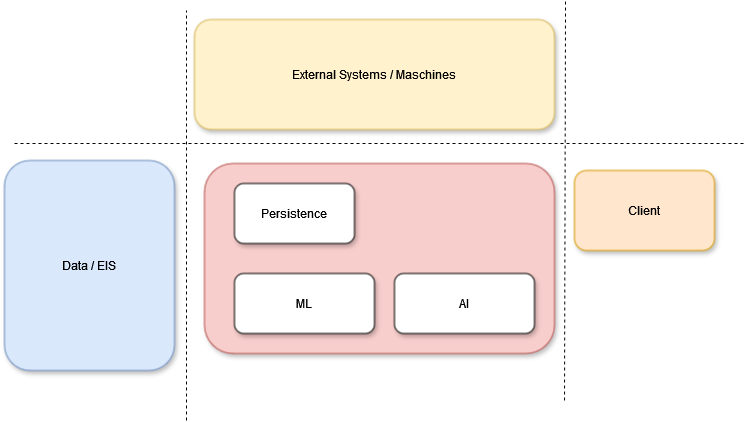
In large systems, these processes are demanding. While the simple stream of Data Input → Data Processing → Machine Learning → AI Model → Output seems trivial, the reality is much more complex. At each stage and phase, numerous considerations and options arise. The data can come from various sources and data containers simultaneously. It might be raw data from sensors or machines, it might come from integrated systems such as data warehouses or data marts, or it might be streamed in real-time from Online Transaction Processing (OLTP) systems, ERP systems, or other streaming devices.
Architectural considerations play a critical role in the success of such systems. The data containers used for data persistence could come from data lakes, non-document-based databases, or strictly typed data models in different formats or sizes. The integration of data and software in handling large volumes of data is an ongoing challenge.
Processing time, data capacities, staging, anonymization in partitions, direct access processing in ISAM (Indexed Sequential Access Method), crash recovery, ETL processes, and data quality checks in ETL—these are all crucial aspects that must be carefully managed. While these issues are common in large systems, they become even more critical in AI-driven systems and require additional attention to ensure system success.
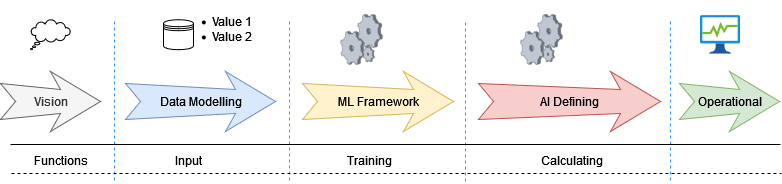
The Heart of the System
The heart of the system lies in the processing of data by developed and refined machine learning (ML) algorithms, which make decisions based on that data. The choice of framework for building these algorithms depends on the specific goals of the system. Popular options include TensorFlow and PyTorch for deep learning, while scikit-learn is often used for more conventional machine learning tasks.
To manage the entire process of training, testing, and refining these models, efficient workflows are essential. Tools like TensorFlow Extended (TFX) can be used for end-to-end automation, while PyTorch Lightning offers structured experimentation and easier deployment. During this phase, feature engineering plays a crucial role in designing input variables that optimize the performance of the model.
Cloud-Based AI and ML Platforms
Managing large datasets and running intensive computations can place significant strain on local hardware. This is where cloud platforms like Google AI Platform, AWS SageMaker, and Azure Machine Learning become invaluable. These services allow for training models at scale, managing complex data pipelines, and performing resource-intensive computations without the need for dedicated hardware infrastructure. They also offer distributed training, enabling data to be processed across multiple servers at once, which helps accelerate model development.
Crucially, these platforms simplify scaling and deployment. Once the application is ready to be launched to a broader audience, cloud services enable smooth integration with real-time production environments.
In any intelligent system, learning is continuous. Once the model is live, a pipeline should be set up to feed it new data over time. This enables the model to learn and adapt, maintaining accuracy as new trends and patterns emerge. For continuous feedback, tools like AutoML (Google AutoML or H2O.ai) can be considered, as they automatically retrain models with fresh data.
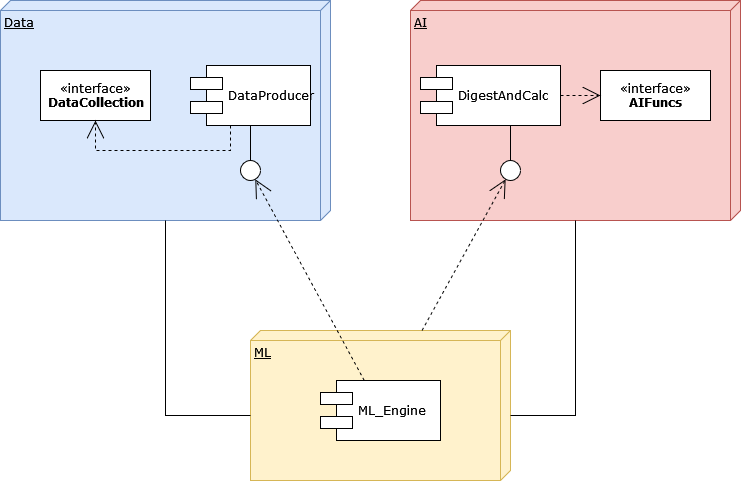
The AI Application’s Logical Engine
In any intelligent system, continuous learning is essential. Once the model is deployed, a pipeline should be set up to feed it new data regularly. This allows the model to evolve and maintain its accuracy as new trends and patterns emerge. Tools like AutoML (e.g., Google AutoML or H2O.ai) can automate the retraining of the model with fresh data, ensuring ongoing adaptation.
Once the data is flowing and the models are ready, the next step is to structure the application logic. This acts as the 'brain' of the AI system, driving its decision-making process. APIs can be developed to expose the model’s insights, allowing the application to make predictions or deliver recommendations.
Frameworks such as Flask, Django, or FastAPI (when using Python) are suitable choices for building these APIs, especially when combined with Docker for portability and scalability. For large-scale model deployment, tools like TensorFlow Serving or NVIDIA Triton Inference Server are optimized for efficient model serving and low-latency predictions.
Testing is a crucial step to ensure the system performs as intended. This includes verifying model accuracy, ensuring smooth data processing, and monitoring the system’s responsiveness. Logging and monitoring tools such as Prometheus and Grafana are helpful for tracking performance, detecting data drift (if there are changes in data patterns), and identifying error rates.
Once the system is tested and validated, scaling might be required to accommodate growing demand. Cloud infrastructure provides the flexibility for horizontal scaling (adding more machines) or vertical scaling (increasing resources on a single machine), facilitating the smooth expansion of the application.
Ensuring Successful AI Development: Key Practices
As the AI framework evolves, maintaining proper documentation is essential for ensuring reproducibility, supporting collaboration, and aiding troubleshooting. When the application handles sensitive or personal data, compliance with data privacy regulations such as GDPR or CCPA is critical, along with adherence to ethical AI practices that minimize bias.
Each stage in building an AI-powered application adds to a complex structure, with data, algorithms, infrastructure, and cloud computing integrating to form a cohesive system.
With a structured approach, a solid foundation for AI application development is established, providing the technical depth and strategic foresight necessary to navigate large-scale AI projects effectively.
Data Flow in AI Systems: Processing and Continuous Learning for Real-Time Insights
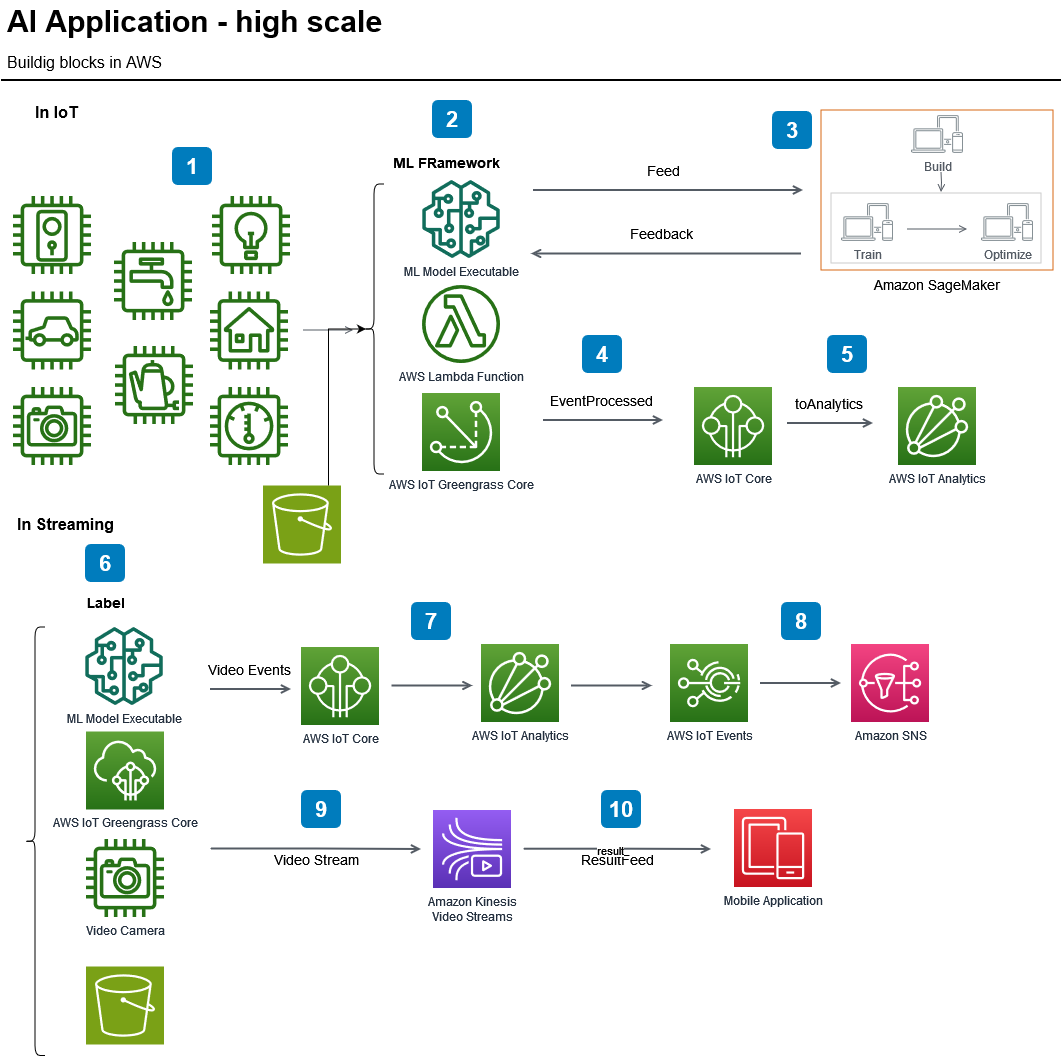
This example illustrates a dataflow approach in which a bulk data unit (e.g., a video sequence) is processed and prepared for use in AI algorithms. While application-dependent, this example follows the processing of a single data unit, such as a video with many frames (where the number of frames depends on the frames-per-second rate). Here, the entire video sequence is used as a dataset, but each frame can be processed independently.
In a system like a face recognition AI, individual frames allow the model to identify a face in each image and track its movement across frames, such as a person walking through a square. By observing frames over time, the AI system can detect patterns, predict next steps, and anticipate behavior based on data from other similar videos. Thus, the model may learn a person’s movement patterns in various scenarios, predicting actions by comparing them with previously learned behaviors.
The diagram would describe a data collection phase, where each video sequence (or data bulk) is gathered and processed through machine learning algorithms. Once processed, outputs such as serialized objects, data marts, or mathematical matrices are stored in a persistence layer. If the data contains events requiring immediate action by an AI model, the system would invoke the necessary AI interfaces, then terminate the current operation.
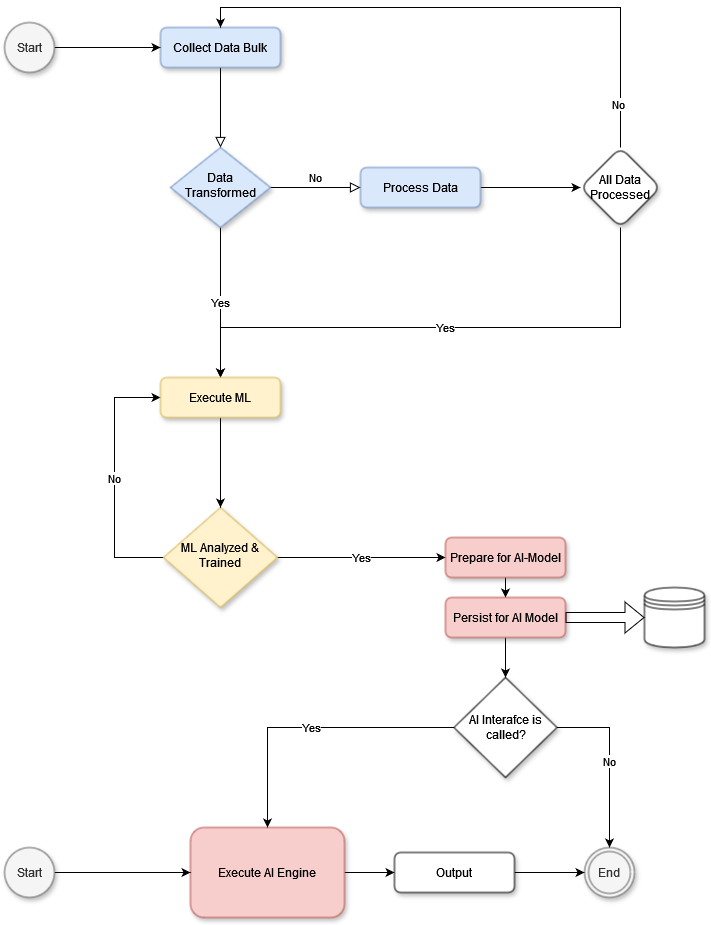
In live ML or AI systems, this workflow becomes more complex. Just as humans continually learn and adapt, AI learning is ongoing, running in parallel with other processes. Multiple specialized threads allow for continuous training and adaptation, so the system remains responsive and relevant as new data is integrated.
In essence, this example emphasizes the importance of data flow and parallel processing in a scalable AI system, balancing immediate responses with the need for continuous learning.
Runtime Environment and Backend Non-Functional Requirements
| Term | Definition |
|---|---|
| AI (Artificial Intelligence) | The simulation of human intelligence in machines that are programmed to think, learn, and solve problems autonomously or semi-autonomously. |
| ML (Machine Learning) | A subset of AI that focuses on training algorithms to recognize patterns in data and make predictions or decisions without explicit programming for each task. |
| Real-Time Processing | The ability of a system to process and respond to data as it is received, providing outputs or results almost instantaneously. |
| Non-Functional Requirements | Characteristics of a system such as performance, scalability, security, and usability, which define how a system operates rather than what it does. |
| Data Marts | Specialized storage structures designed to serve a specific purpose, such as optimizing data for analytics. They typically contain aggregated data for easier and faster access. |
| Data Lake | A storage system that holds large amounts of raw data in its original format until it is needed for analysis. Data lakes support various data types, including structured, semi-structured, and unstructured data. |
| ETL (Extract, Transform, Load) | A data integration process where data is extracted from various sources, transformed into a suitable format, and loaded into a data warehouse or data mart. |
| ISAM (Indexed Sequential Access Method) | A method for data retrieval that allows data to be accessed in a sequence or directly through an index, commonly used in high-performance data systems. |
| Data Pipeline | A set of processes and tools used to transport, transform, and load data from one system to another, enabling real-time or batch data processing. |
| Data Quality Checks | Processes to ensure that data is accurate, consistent, complete, and reliable. Quality checks are crucial for maintaining the integrity of data used in AI systems. |
| TensorFlow & PyTorch | Popular open-source libraries used for building and deploying machine learning and deep learning models. TensorFlow is known for its scalability, while PyTorch is favored for ease of experimentation and flexibility. |
| Cloud-Based AI and ML Platforms | Platforms such as Google AI Platform, AWS SageMaker, and Azure Machine Learning that provide tools for building, training, and deploying machine learning models in the cloud. |
| Distributed Training | A method of training ML models across multiple machines or processing units simultaneously, allowing for faster model development with large datasets. |
| AutoML (Automated Machine Learning) | A suite of tools and methods that automates the ML model-building process, from data pre-processing to model training and tuning. Examples include Google AutoML and H2O.ai. |
| APIs (Application Programming Interfaces) | A set of protocols and tools that allow different software applications to communicate. APIs are essential for exposing machine learning insights and enabling real-time decision-making. |
| Docker | An open-source platform used to develop, package, and deploy applications in lightweight containers, enhancing portability and scalability. |
| TensorFlow Serving & NVIDIA Triton Inference Server | Specialized serving systems that optimize machine learning model deployment, enabling low-latency, high-efficiency predictions for production environments. |
| Logging and Monitoring (Prometheus & Grafana) | Tools used to collect, store, and visualize performance metrics. These tools help track system performance, data drift, error rates, and other key indicators to ensure stability and efficiency. |
| Horizontal Scaling | Adding more machines to increase a system's processing power, allowing it to handle more workload without overloading a single machine. |
| Vertical Scaling | Increasing the resources (e.g., CPU, memory) of a single machine to enhance its performance. This approach is often used when data volumes are manageable by one machine with sufficient power. |
| Data Privacy Regulations (GDPR & CCPA) | Laws governing the collection, storage, and use of personal data to protect user privacy. Compliance with these regulations is essential in AI applications, especially those handling sensitive information. |