
- Details
- Geschrieben von Joel Peretz
- Kategorie: Uncategorised
- Zugriffe: 73700
Blockchain: El Dorado or Mirage?
Is Blockchain Really as Simple to Implement as It Seems? A Simple Showcase

<<will be continued>>
The blockchain hype subsided as quickly as it ignited. It was, more or less, like the DotCom (.com) bubble that imploded with a deafening silence, dragging many companies into the depths of IT history, swallowing hopes and assets, and making individuals and organizations more cautious in their planning. The industrial “fake-it-until-you-make-it” approach proved to be hazardous. The fast revenue potential at the beginning can create a low-pressure area on the marketing maps of a company’s future.
As history often repeats itself, the lessons learned by one generation, which eventually exits the market, are rarely retained by the next. Instead, the same mistakes are repeated. Some individuals become wealthy from these cycles—whether through foresight or luck is questionable—while the majority lose significantly. There are not many technologies that “stick” for the long run, and those that do are usually built on the stable foundations of consistent developments from the past. A few others have begun as student projects with simple technology stacks but solid theoretical groundwork and eventually became giants. Many, however, started with loud fanfare and ambitions but dwindled into exotic remnants of aspirations that were pursued too hastily by individuals too young or impatient to fully think things through.
In the north, large server farms were constructed to accommodate blockchain technology. These would enable processes to be executed autonomously by machines, allowing decisions and actions to occur without direct human intervention. New frameworks were pushed forward to standardize these processes. Companies competed and raced, as they always have, to be the first or the strongest brand leading the industry. Blockchain was envisioned as the industry of the future.
None of this was new in the way it unfolded. However, the basics and fundamentals were ignored. Blockchain itself is a simple yet brilliant concept. Everything surrounding it—servers, connections, communication protocols, project management methods, and so on—is not different or new compared to technologies that have existed for decades. The same problems remain, requiring the same resources and skills to solve them.
The cloud arrived, followed by ML and AI, and suddenly everyone was talking about billions of dollars, euros, yen, and other currencies waiting to be lavishly collected. Young managers swayed in dreams of cushioned clouds made of money. The golden rule of “there are always two sides to a coin” was forgotten, and the superficial attachment to buzzwords and idioms slammed ambitions hard against the office walls.
Experienced consultants in this domain understand what it takes to scale up later, but they also know how to skip unnecessary steps at the right time. They can accurately calculate risks and anticipate the pitfalls of discovering too late in the development process that the chosen tech stack is no longer viable. Even so, if the project is carefully planned—and careful does not necessarily mean slow—surprises that arise can still be managed with minimal loss of time and effort.
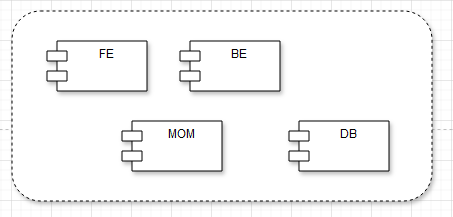
Basic Component types
There’s no need to go around in circles: these new technologies and tools do have undeniable benefits. They offer instant, visible advantages—just a few clicks, and you can see results because the “boilerplate” code is automatically generated. But what about the other aspects that are critical to companies? Isn’t this bordering on the “smoke-and-mirrors” antipattern? Flashy, fast results with piles of boilerplate code that remain unfamiliar, untested, and that still require extensive customization and refinement to be usable.
Even SPA (Single Page Applications) need careful design and thoughtful planning. The rush for rapid, visual outcomes often overlooks the deeper, structural considerations that are the foundation of sustainable, scalable solutions.
The easily accessible automation of AI, delivering impressive results like those seen in ChatGPT, creates the illusion that anyone can now "fake-it-until-you-make-it." To some extent, this is true—at least for the first part.
A young manager posts on LinkedIn, claiming that experience is unnecessary, a beginner can outperform expectations, and expertise can simply be bought. The flawed logic doesn’t seem to occur to her: who is going to sell this knowledge and the insights that come with experience? And what will it cost? If experience isn’t necessary, why even bother buying it? Does experience only refer to the number of working years, or does it also encompass the depth of understanding and lessons learned? This upfront delusional and fundamentally wrong approach exposes a lack of understanding of the complexity and skill required in such situations.
Critical factors for success—such as diligence, the will to learn, and the drive to progress with the promise of long-term benefits—are often underestimated. Just because the market is hungry and thirsty for resources doesn’t mean that expertise is endlessly exploitable. In fact, this mindset can demotivate skilled individuals. The more advanced someone’s skills are, the harder it is for others to fully grasp what they’re explaining. This is because beyond academic knowledge lies practical experience, gained in the field, which is absolutely essential.
This brings us back to blockchains. Is it possible to apply the "keep it simple" rule to blockchain-based systems in a way that increases data security and builds more reliable, safer business processes—without diving into an ocean of massive investments and risks by adopting large-scale frameworks from the start?
I believe the answer is yes. Let’s start by simply examining how a blockchain is constructed and expand the discussion from there.
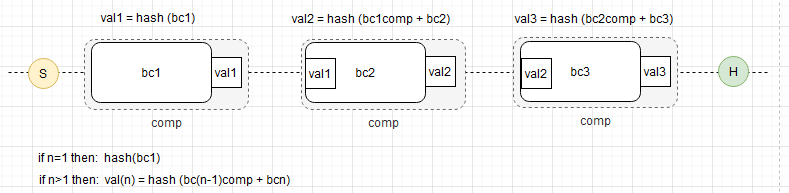
Blockchain (S= Start, H-Head)
There are “massive” frameworks with steep learning curves, accompanied by significant project management risks, as previously mentioned. The investments required can be substantial. However, the greatest benefits of data security can often be achieved with minimal overhead.
The basic application will consist of the usual layers: Front End, Back End (including Business Logic and a Persistence Shadowing Layer), the Middleware (MOM) layer where necessary, and of course, the persistence layer where the data is stored.
In most cases where blockchains are a viable solution, aspects such as scalability and latency are of critical importance. While there is no “one-size-fits-all” approach, it’s highly probable that a microservices architecture will be the goal. For this discussion, even though it’s not mandatory, it will be assumed.
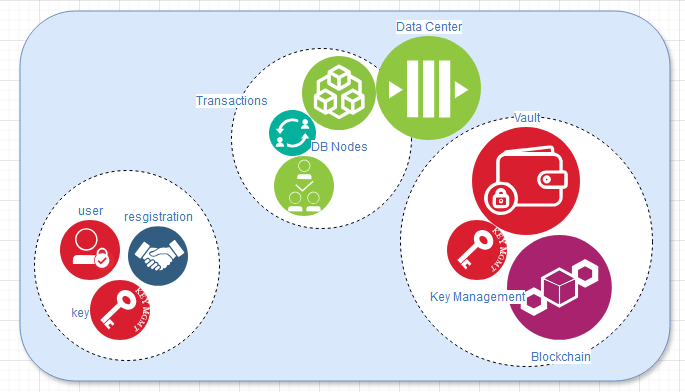
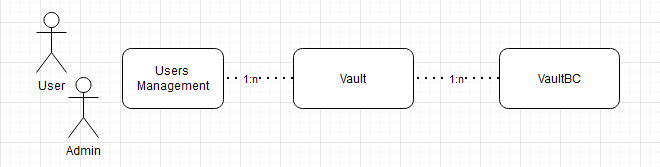
The blockchains will be created and maintained as encrypted data within a wallet. Each user will generate and store their private keys locally as part of the PKI (Public Key Infrastructure), while the corresponding public keys will be uploaded and securely stored in a vault. Users can maintain multiple vaults, each aligned with specific business purposes and goals.
The blockchain itself is a piece of hashed data that also stores its own calculated hash value, which includes the hash of the previous block in the chain. By design, a block cannot be modified—only the last block can be edited, and even then, only under predefined business rules. A vault can be created or deleted, but modifying an earlier block in the chain would require immense computational power, which is unnecessary and impractical in most cases.
In this context, a microservice can initially run locally on-premise during feasibility checks, POC, and prototyping phases, and then scale up as the release rolls out into production. Securing investments can be approached at multiple levels. For example, container technology is a cost-effective option, though it may quickly become expensive depending on the challenges the system encounters during operation.
Building a microservice is relatively straightforward once its purpose is clearly defined and its ports and externally attached volumes are configured. A microservice might serve as a frontend component or fulfill other roles within the system. Additionally, within a virtualized runtime environment, it is possible to integrate databases and messaging providers, which can often be exchanged later—depending on the abstraction level implemented. For instance, starting with a MySQL database and transitioning to a MongoDB NoSQL solution is feasible, provided that no non-ANSI elements are used and an abstraction layer is in place to automate the conversion process.
The idea of coding and running on one platform, ensuring it can run anywhere where the containerized execution engine is installed—in our case, Docker—is highly appealing. It is very reasonable to use frameworks that implement established standards, with trackable change management and release notes, rather than forfeiting the enormous benefits they offer.
Our microservices, as the foundational components, include the frontend, backend, databases, and messaging middleware. To automate and facilitate crash recovery during deployment, a Terraform script will be generated. For a controlled startup and shutdown of the system, a Docker Compose file will be created.
Aspects like logging and monitoring can initially be deferred until the network traffic and data capacities reach the predicted scale. Tools like the ELK Stack or Morpheus can be introduced later, as well as Hadoop and data lakes or schema-less data containers. In the early stages, these are not necessities. Instead, a small, scalable solution will suffice—for example, using SLF4J instead of a more complex framework or local caching instead of Redis instances.
Our microservice will employ a client that can be simple, such as React or Angular, while leveraging a robust and extensive backend framework like Spring and Spring Boot with Java and RESTful services.
Scaling This Blockchain Application
Scaling this blockchain application can be achieved by either scaling up or increasing the number of the smallest execution units, known as microservices—commonly referred to as containers in intermediate technical terminology. With a properly configured setup, scaling becomes straightforward, as it simply involves adjusting the number of containers, assuming sufficient resources such as memory and storage are available. For example, this could mean increasing the number of containers from three to five or from eighteen to twenty, depending on the specific requirements.
Using scripting infrastructures and cloud platforms, scaling is theoretically limitless. In this implementation, horizontal scaling is applied through two servers—or potentially a server farm—managed by a Kubernetes cluster for container orchestration.
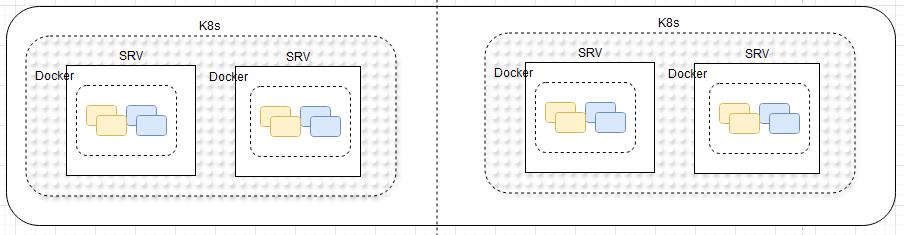
Horizontally Scaled Servers in Kubernetes-Clustered, Containerized Microservices
The concept behind data safety in a blockchain is its ability to be validated. If the blockchain is tampered with, it becomes invalid and unusable, prompting further measures to be taken. The data is stored across multiple data centers, each holding identical copies of the blockchain. During read or write transactions, the hashes can be compared across these instances to ensure validation.
Data replication occurs during the processes of vault and blockchain creation or deletion. As mentioned, the only blockchain that can be edited is the most recent one within a vault, commonly referred to as "the head." The validation of blockchain hashes for ensuring integrity can be performed through peer-to-peer connections.
Here’s a possible, simple, self-tailored schema for implementing this approach:
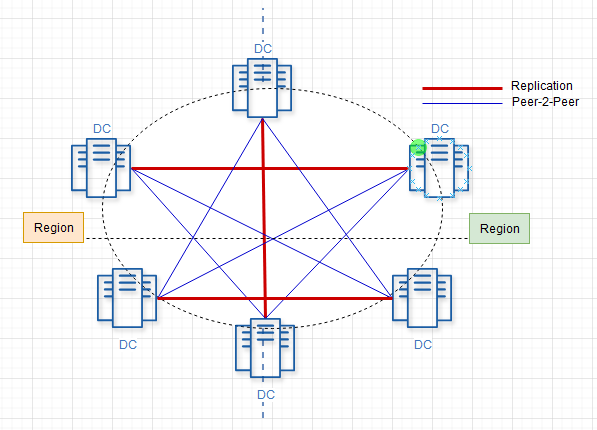
Leveraged Distributed Persistence
Glossar
| Term | Definition |
|---|---|
| Blockchain | A distributed ledger technology that stores data in encrypted blocks, ensuring immutability and security. Each block contains a hash of the previous block, ensuring the integrity of the entire chain. |
| Client Lock-in | The phenomenon where businesses become dependent on a specific vendor or platform, making it difficult to switch to alternatives due to technical or financial constraints. |
| Microservices | Architectural style that structures an application as a collection of loosely coupled services. Each microservice corresponds to a specific business function and can be developed, deployed, and scaled independently. |
| Containers | A lightweight, standalone package that contains everything needed to run a piece of software, including the code, runtime, libraries, and dependencies. In blockchain applications, they are used to encapsulate microservices. |
| Kubernetes | An open-source platform designed to automate the deployment, scaling, and management of containerized applications, often used in cloud environments to orchestrate microservices. |
| Docker | A platform that enables developers to create, deploy, and run applications in containers, ensuring consistency across different computing environments. |
| Terraform | An open-source infrastructure-as-code software tool used for building, changing, and versioning infrastructure securely and efficiently, often used for managing containers and cloud resources in blockchain applications. |
| Docker Compose | A tool used for defining and running multi-container Docker applications. It allows developers to define the services, networks, and volumes for their applications, facilitating containerized application startup and shutdown. |
| ELK Stack | A collection of three open-source tools—Elasticsearch, Logstash, and Kibana—that help manage and analyze large volumes of data, often used for logging and monitoring in cloud applications and blockchain solutions. |
| Morpheus | Likely referring to a software platform or tool used for managing cloud resources and infrastructure, including services such as monitoring, orchestration, and deployment. |
| Hadoop | An open-source framework that enables distributed storage and processing of large datasets using clusters of computers. Commonly used in big data environments, including blockchain applications, for handling vast amounts of data. |
| Data Lakes | A storage repository that holds vast amounts of raw data in its native format until it is needed for analysis. Often used in conjunction with blockchain and big data technologies. |
| RESTful Services | A set of web services that follow the principles of Representational State Transfer (REST). These services are stateless, scalable, and used for communication between microservices or client applications in a blockchain environment. |
| Spring Framework | An open-source framework for building enterprise Java applications. It is often used in blockchain applications for building robust backends and providing support for microservices and RESTful APIs. |
| Spring Boot | A framework built on top of Spring that simplifies the process of setting up and configuring Java-based applications, commonly used in blockchain applications to speed up the development of backend services. |
| Public Key Infrastructure (PKI) | A framework for managing digital keys and certificates, allowing secure communication and transactions within blockchain applications by verifying identities and ensuring data security. |
| Vault | A secure storage system used for storing and managing secrets such as API keys, passwords, and certificates in blockchain applications. |
| Hashing | A cryptographic technique used to convert data into a fixed-length string of characters, which serves as a unique identifier for data. In blockchain, hashes are used to link blocks and ensure data integrity. |
| Horizontal Scaling | The process of adding more instances or resources to a system, such as additional servers or containers, to handle increased workload or demand in blockchain applications. |
| Vertical Scaling | The process of adding more resources, such as CPU or memory, to an existing server to increase its capacity, often contrasted with horizontal scaling. |
| Persistence Layer | The layer in an application responsible for storing and retrieving data from permanent storage systems, such as databases, in blockchain solutions. |
| Business Logic Layer | The layer of an application that processes data according to the rules and operations of the business, often coupled with blockchain applications to manage transactions and ensure data integrity. |
| Middleware (MOM) | A software layer that sits between the backend and frontend of an application, handling communication, message routing, and other necessary operations to support blockchain services. |
| AI/ML Integration | The process of integrating Artificial Intelligence (AI) and Machine Learning (ML) algorithms into a system, including blockchain applications, to make decisions, automate processes, and optimize business logic. |
| Blockchain Application Architecture | The structural design of a blockchain-based system, including components like frontend, backend, business logic, persistence, middleware, and more, required to build and maintain blockchain solutions. |
| Scalability | The ability of a system to handle an increasing amount of work or its potential to accommodate growth, particularly in terms of increasing the number of containers or instances in a blockchain solution. |
- Details
- Geschrieben von Joel Peretz
- Kategorie: Uncategorised
- Zugriffe: 66250
Building a Powerful AI Application: Complementary to Architectural Planning
Runtime Environment and Backend Non-Functional Requirements

Mistaken ideas about software architecture sometimes arise, typically from those without years of hands-on experience. While previous articles touch on architectural concepts, they rarely go deeply or offer concrete examples. Often, managers and other non-technical professionals can imagine general aspects of architecture at an abstract level, drawing on technical summaries. However, truly understanding complex technical systems requires direct experience—much like a firefighter intimately familiar with water pressure dynamics during a critical moment, or a racecar driver who can feel the nuanced difference in tire performance when pressure varies under high-speed conditions in a turn. Both instances reflect how subtle, practical knowledge shapes the understanding of systems in ways theory alone cannot.
When asked, 'What is the best system or software architecture?' it often signals either a test of the responder’s expertise or that the person asking may not fully understand architecture. The question is akin to asking, 'What’s the best architectural design for a building?' without specifics. To truly answer, one must know the where, what, why, who, and when. Consider if the project is a bridge over desert sands or an extension to a museum in a freezing climate. Similarly, designing a small dinghy versus a container ship involves entirely different requirements, resources, components, and regulations, even though both are watercraft.
Software architecture parallels these physical examples: it’s the optimal arrangement of components, systems, and integrations to meet the specific requirements of the project. Even when starting from scratch, a software architecture will often integrate or coexist with other systems, each with its own architecture. Additionally, most software is built on top of, or within, other architectural layers that influence design choices. So, just as with physical architecture, there is no universal 'best'—only the best fit for the given situation.
In a previous article, we presented a diagram illustrating a potential system architecture built in the AWS cloud. AWS provides an N-Tier infrastructure, which means it is organized in multiple layers that separate concerns and simplify scaling. AWS offers a wide array of ready-made services and products that can be used as building blocks. These components must be configured and interconnected to work as a cohesive system. For instance, an EC2 server running a Unix-based operating system might interact with database instances like Oracle or Redis to handle data.
While the cloud itself follows an N-Tier structure, additional architectural patterns can be layered on top of it. For example, a Service-Oriented Architecture (SOA)—a component-based architecture—can be implemented within this environment. Various architectural patterns are available for system design, each created to solve specific recurring challenges. Some commonly used patterns include Pipes and Filters, Blackboard, Model-View-Controller (MVC), and Microservices. Selecting the right pattern depends on the specific requirements and goals of the application.
The choice of architecture for a system depends on what we aim to accomplish with it and the specific nature of the system itself. This decision-making process is similar to selecting the appropriate tools and materials based on the project type. For instance, when constructing a new village, we would use trucks to transport sand and rubble, not milk. When building a bunker, we would need substantial metal reinforcement before pouring in cement. Although both examples involve construction, the methods and materials vary widely due to their different requirements.
In technology, architecture is tailored similarly. If our goal is to broadcast traffic alerts that cars can pick up like a radio signal, the architecture would differ significantly from an Online Transaction Processing (OLTP) system, which processes telecommunications packets over the internet. These systems diverge in terms of data volume, target users, and required speed.
To avoid an overly lengthy discussion, I'll highlight a few essential architectural considerations. Afterward, we’ll examine the architecture of a high-availability CRM system based on XAMPP, covering key points without going intointo every aspect. Finally, we’ll look at a cloud-based platform for AI and ML that leverages both local, on-premise components and cloud integrations, with flexibility to use elements beyond AWS.
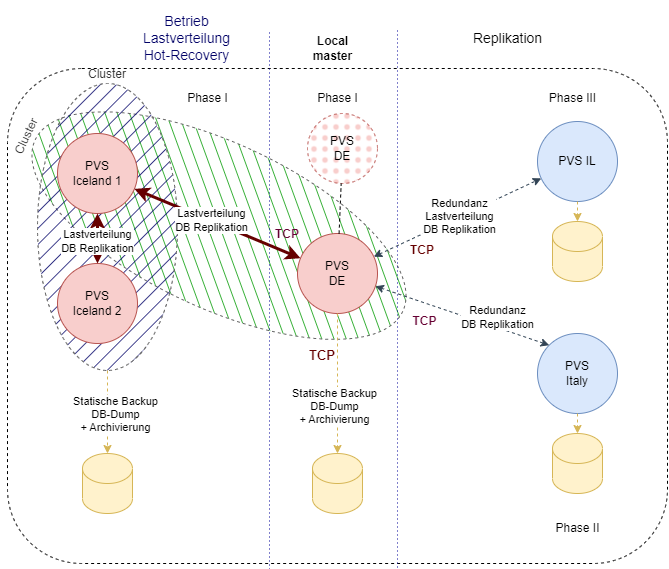
The diagram is in German captions: later in English as well
This architecture is a budget-conscious approach designed to ensure high availability and crash recovery. It’s built on a Unix operating system running an Apache Web Server and MySQL RDBMS.
At its core is a Joomla-based CRM system hosted on a centralized ‘master’ server. This master server is configured for direct user access, while additional ‘slave’ servers handle load balancing. Load balancing is managed via Apache’s software-based configurations, allowing for horizontal scalability as the system expands.
MySQL servers use replication to synchronize data across instances, ensuring data redundancy and reliability. In case of a server failure, this setup minimizes downtime and data loss. Data backups are also automated and stored on independent servers, located in different countries to provide an added layer of security and regulatory compliance.
Users can customize this architecture by examining regulatory requirements, disaster recovery plans, and associated costs, depending on specific organizational needs.
Though this is not a cloud-based architecture and doesn’t utilize proprietary software modules, it meets the requirements for the expected user load, data volume, and network traffic. The system doesn’t demand ultra-low latency or real-time processing, as it primarily serves dynamically generated HTML pages to users without performing on-the-fly calculations.
Extra servers improve resilience, storing backup data and reducing crash recovery time in events like a cyberattack. Automation scripts and a ‘watchdog’ monitoring process enhance system uptime by quickly identifying issues. In case of a failure, the system can restart the Apache daemon programmatically, enabling rapid recovery within seconds due to data replication and the restart of the background Unix process.
What are the so-called non-functional requirements for a high-performance ML and AI machine in the cloud? What are the considerations when building a system that not only recognizes faces but also tracks the figure across a square? Let’s say we have 200-500 surveillance cameras surrounding a major city. Not all of them are monitoring a square, some are focused on traffic, but the system performs the same function: it classifies single frames on demand and logically connects them between frames.
We will continue this discussion soon. We cannot cover all aspects at once, but we will focus on a few aspects each time.
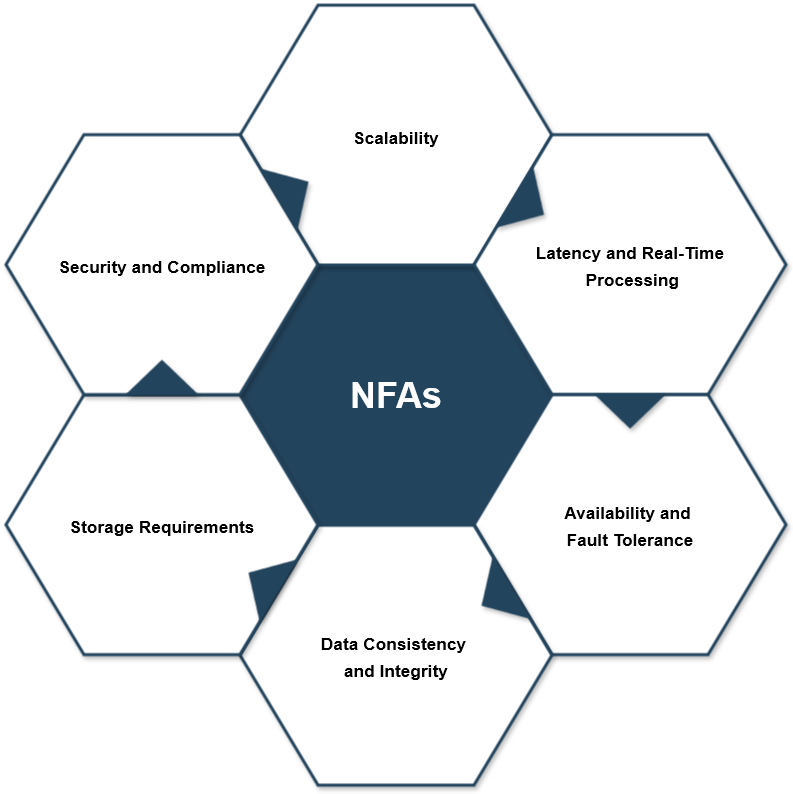
Scalability
To handle an increasing volume of data from more cameras, the system should be able to scale both horizontally and vertically. Horizontal scaling involves adding more machines to distribute workloads, while vertical scaling means upgrading individual machines. This ensures efficient real-time processing, even as the system expands.
Latency and Real-Time Processing
Low latency is crucial for applications like figure tracking, where quick responses are needed. To minimize delays, edge computing can process data closer to the source (e.g., on the cameras themselves) before sending it to the main system for analysis, reducing transmission delays.
Availability and Fault Tolerance
To ensure the system remains operational without interruption, high availability is essential. This can be achieved by implementing redundancy and failover mechanisms, such as using multiple server clusters that take over in case one fails. Real-time services should continue seamlessly even if a component experiences issues.
Data Consistency and Integrity
Maintaining consistent and accurate data is important, but strict real-time consistency isn’t always necessary for all parts of the system. For non-critical data, eventual consistency can be an acceptable model, while real-time processing of crucial information (like tracking movements or sending alerts) should rely on up-to-date data. Proper versioning and validation processes are key for maintaining data integrity across the system.
Storage Requirements
Given the massive amounts of video data generated by the surveillance system, high-capacity and high-throughput storage are necessary. Cloud storage solutions, such as Amazon S3, combined with data lakes or warehouses, can handle the large volume of data efficiently. Clear retention policies for data storage and deletion are important to manage costs and ensure compliance with regulations.
Security and Compliance
Since surveillance footage is highly sensitive, ensuring its security is paramount. The system should implement strong encryption, access control mechanisms, and constant monitoring to prevent unauthorized access. Additionally, it must adhere to data privacy laws, ensuring that data is handled responsibly, with full traceability and accountability.
Glossary
| Term | Definition |
|---|---|
| Software Architecture | The high-level structure of a software system, defining the organization of its components, their interactions, and integration. |
| N-Tier Architecture | A software architecture pattern that organizes a system into multiple layers (e.g., presentation, business logic, data) to separate concerns and enhance scalability. |
| AWS | Amazon Web Services, a cloud computing platform offering various services like compute power, storage, and databases. |
| EC2 | Elastic Compute Cloud, an AWS service that provides resizable compute capacity in the cloud. |
| Unix | A powerful, multi-user, multitasking operating system commonly used for servers. |
| RDBMS | Relational Database Management System, a type of database management system (DBMS) that stores data in a structured format using tables. |
| Oracle | A widely used RDBMS developed by Oracle Corporation. |
| Redis | An open-source, in-memory data structure store, commonly used for caching and real-time applications. |
| SOA (Service-Oriented Architecture) | A software design pattern that structures a system as a collection of services that communicate over a network. |
| Microservices | An architectural style that structures an application as a collection of loosely coupled services, each handling a specific function. |
| Pipes and Filters | An architectural pattern where data flows through a series of processing steps (filters) connected by pipes. |
| Model-View-Controller (MVC) | A software design pattern that separates an application into three main components: the model (data), the view (UI), and the controller (logic). |
| OLTP (Online Transaction Processing) | A class of systems that supports transactional applications, such as processing orders or bank transactions, often involving high-volume data. |
| XAMPP | A free and open-source cross-platform web server solution stack package, consisting of Apache, MySQL, PHP, and Perl. |
| High Availability | A system design approach that ensures a high level of operational performance, uptime, and reliability, often involving redundancy and failover mechanisms. |
| Crash Recovery | The ability of a system to recover from a failure, such as a crash or data corruption, ensuring minimal disruption and data loss. |
| Load Balancing | The distribution of incoming network traffic across multiple servers to ensure efficient resource utilization and availability. |
| Replication | The process of copying and maintaining database objects, such as tables, in multiple locations to ensure data redundancy and high availability. |
| Disaster Recovery Plans | A set of procedures to follow in the event of a system failure, including data recovery and ensuring business continuity. |
| Edge Computing | A distributed computing framework that brings computation and data storage closer to the location where it is needed, reducing latency. |
| Latency | The delay between a user's action and the system’s response, critical in systems that require real-time or near-real-time processing. |
| Fault Tolerance | The ability of a system to continue functioning despite the failure of one or more components. |
| Data Consistency | Ensuring that data remains accurate, reliable, and up-to-date across different parts of the system. |
| Eventual Consistency | A model where data consistency is achieved over time, with the assumption that the system will eventually reach consistency after updates. |
| Cloud Storage | A service that allows users to store data on remote servers accessed via the internet, offering scalability and remote access. |
| Data Privacy Laws | Legal regulations governing how personal data is collected, stored, and shared, ensuring user privacy and security. |
| Encryption | The process of converting data into a code to prevent unauthorized access. |
| Access Control | A security technique that regulates who or what can view or use resources in a computing environment. |
- Details
- Geschrieben von Joel Peretz
- Kategorie: Uncategorised
- Zugriffe: 72550
Die Synergie von MOM und Cloud-Technologien: Optimierung von Skalierbarkeit und Leistung in modernen Anwendungsarchitekturen

- Details
- Geschrieben von Super User
- Kategorie: Uncategorised
- Zugriffe: 69200
Building a Powerful AI Application: From Vision to Implementation
Architecting and Building a Robust AI System: Key Considerations for Scalable Design and Implementation

We are setting out to build a powerful AI application, and, of course, defining the subject matter is the first step. What exactly will this application do, and how will it be useful and usable? While this is always a key question when developing any application, there are additional considerations that come with the nature of the project. This is no ordinary application—it will leverage vast amounts of data and incorporate machine learning (ML), all while aiming to provide real-time or near-real-time results.
This makes it a much more complex endeavor, like constructing a sophisticated machine with many moving parts. Each part of the application is essential and needs to work in perfect sync with the others. However, as with any complex system, we can break it down into smaller, manageable components that can be developed separately.
The framework and phases of this machine, while intricate, align with the architecture of any other large-scale application. During this process, we will adhere to best practices while giving extra focus to certain parts—especially those non-functional requirements and specialized logical units—that are more critical in the context of AI and ML-driven applications.
We could have some parts of the system as subsystems or components that are already available or existing within the infrastructure landscape. Since their role is identical, it ultimately becomes a business decision whether to use these existing components or create new ones. However, there may be cases where integrating these existing components is either not feasible or not cost-effective, in which case they will be ruled out. Therefore, we approach the process as if no existing components are available for use.
The Vision
What is the blueprint of the application, and what exactly will it do? Defining this is crucial because it will influence how we select the complexity of algorithms and the data to be used. Will the application handle structured data or document-based data? Is it going to be an automated tool, a recommendation system, or a strategy-driven platform that is event-driven and operates in real-time? These decisions will directly affect the performance requirements and, in many cases, will guide the selection of architecture and technology stack.
The “Factory”
Imagine a factory that produces something unique as the output of the entire production process—much like what the AI application will generate. To achieve this, it requires a vast amount of raw data, which is stored, processed, retrieved, cached, and regenerated to create data marts. Data acts as the lifeblood of the system, flowing through the various machines that prepare it. These machines feed the machine learning models, enabling the AI's logical units to process the data and produce the desired output.
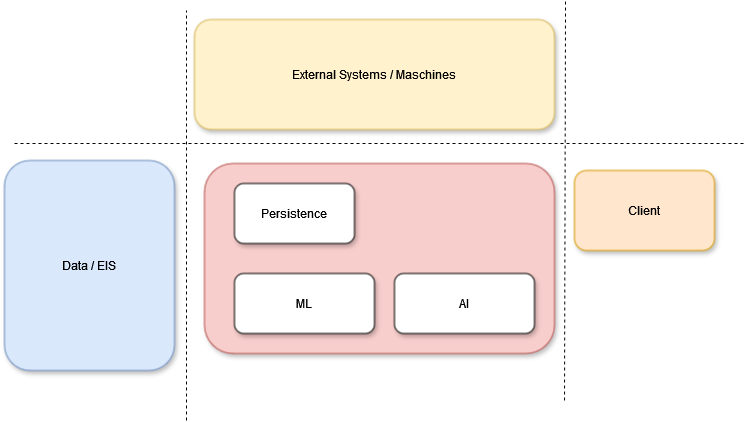
In large systems, these processes are demanding. While the simple stream of Data Input → Data Processing → Machine Learning → AI Model → Output seems trivial, the reality is much more complex. At each stage and phase, numerous considerations and options arise. The data can come from various sources and data containers simultaneously. It might be raw data from sensors or machines, it might come from integrated systems such as data warehouses or data marts, or it might be streamed in real-time from Online Transaction Processing (OLTP) systems, ERP systems, or other streaming devices.
Architectural considerations play a critical role in the success of such systems. The data containers used for data persistence could come from data lakes, non-document-based databases, or strictly typed data models in different formats or sizes. The integration of data and software in handling large volumes of data is an ongoing challenge.
Processing time, data capacities, staging, anonymization in partitions, direct access processing in ISAM (Indexed Sequential Access Method), crash recovery, ETL processes, and data quality checks in ETL—these are all crucial aspects that must be carefully managed. While these issues are common in large systems, they become even more critical in AI-driven systems and require additional attention to ensure system success.
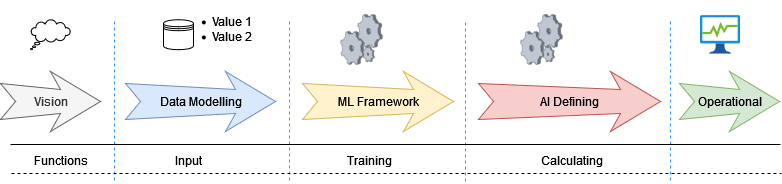
The Heart of the System
The heart of the system lies in the processing of data by developed and refined machine learning (ML) algorithms, which make decisions based on that data. The choice of framework for building these algorithms depends on the specific goals of the system. Popular options include TensorFlow and PyTorch for deep learning, while scikit-learn is often used for more conventional machine learning tasks.
To manage the entire process of training, testing, and refining these models, efficient workflows are essential. Tools like TensorFlow Extended (TFX) can be used for end-to-end automation, while PyTorch Lightning offers structured experimentation and easier deployment. During this phase, feature engineering plays a crucial role in designing input variables that optimize the performance of the model.
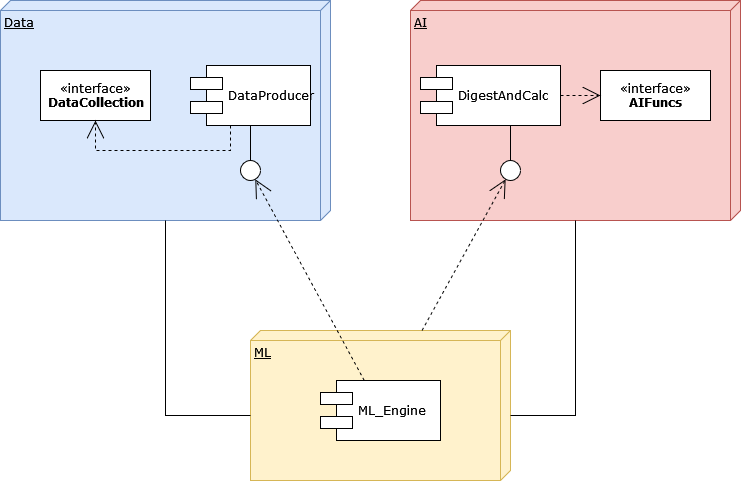
Cloud-Based AI and ML Platforms
Managing large datasets and running intensive computations can place significant strain on local hardware. This is where cloud platforms like Google AI Platform, AWS SageMaker, and Azure Machine Learning become invaluable. These services allow for training models at scale, managing complex data pipelines, and performing resource-intensive computations without the need for dedicated hardware infrastructure. They also offer distributed training, enabling data to be processed across multiple servers at once, which helps accelerate model development.
Crucially, these platforms simplify scaling and deployment. Once the application is ready to be launched to a broader audience, cloud services enable smooth integration with real-time production environments.
In any intelligent system, learning is continuous. Once the model is live, a pipeline should be set up to feed it new data over time. This enables the model to learn and adapt, maintaining accuracy as new trends and patterns emerge. For continuous feedback, tools like AutoML (Google AutoML or H2O.ai) can be considered, as they automatically retrain models with fresh data.
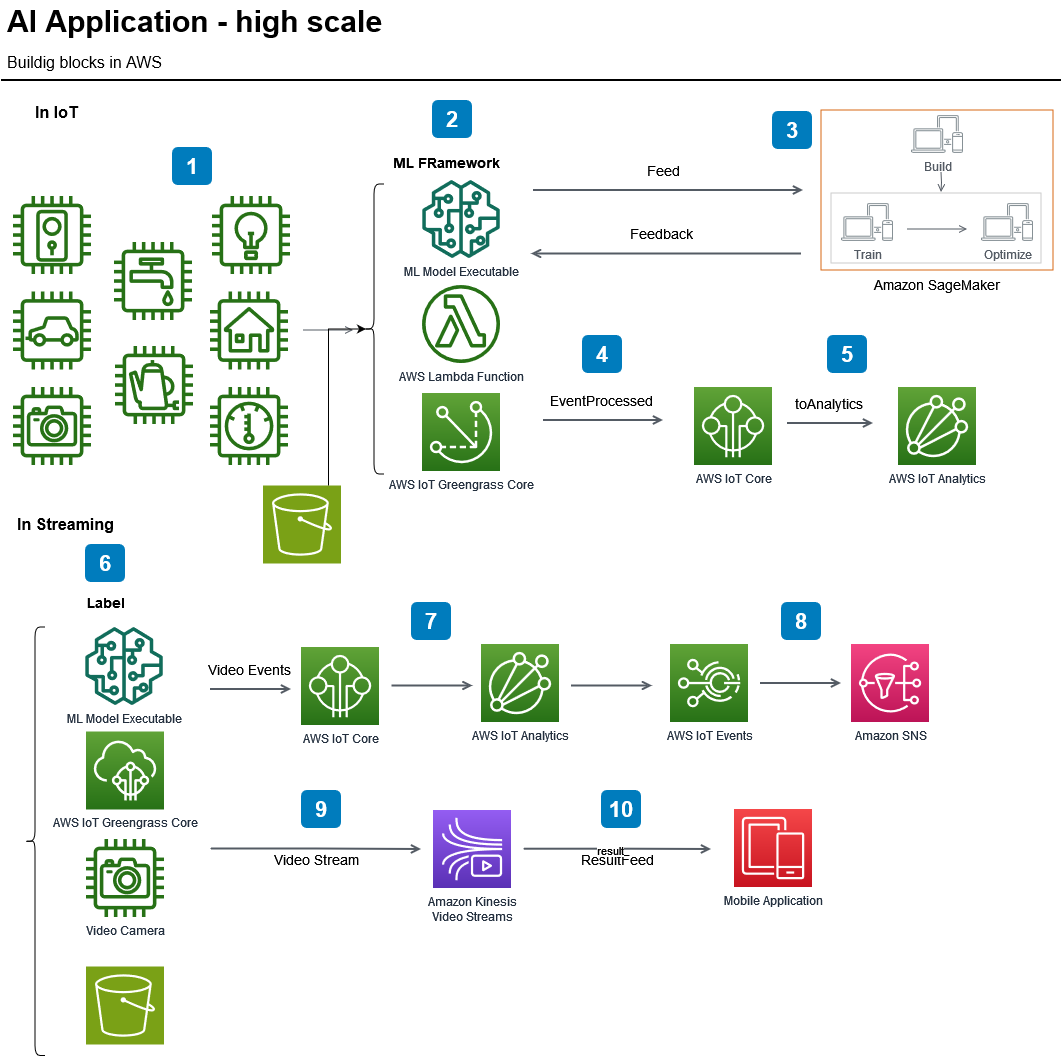
The AI Application’s Logical Engine
In any intelligent system, continuous learning is essential. Once the model is deployed, a pipeline should be set up to feed it new data regularly. This allows the model to evolve and maintain its accuracy as new trends and patterns emerge. Tools like AutoML (e.g., Google AutoML or H2O.ai) can automate the retraining of the model with fresh data, ensuring ongoing adaptation.
Once the data is flowing and the models are ready, the next step is to structure the application logic. This acts as the 'brain' of the AI system, driving its decision-making process. APIs can be developed to expose the model’s insights, allowing the application to make predictions or deliver recommendations.
Frameworks such as Flask, Django, or FastAPI (when using Python) are suitable choices for building these APIs, especially when combined with Docker for portability and scalability. For large-scale model deployment, tools like TensorFlow Serving or NVIDIA Triton Inference Server are optimized for efficient model serving and low-latency predictions.
Testing is a crucial step to ensure the system performs as intended. This includes verifying model accuracy, ensuring smooth data processing, and monitoring the system’s responsiveness. Logging and monitoring tools such as Prometheus and Grafana are helpful for tracking performance, detecting data drift (if there are changes in data patterns), and identifying error rates.
Once the system is tested and validated, scaling might be required to accommodate growing demand. Cloud infrastructure provides the flexibility for horizontal scaling (adding more machines) or vertical scaling (increasing resources on a single machine), facilitating the smooth expansion of the application.
Ensuring Successful AI Development: Key Practices
As the AI framework evolves, maintaining proper documentation is essential for ensuring reproducibility, supporting collaboration, and aiding troubleshooting. When the application handles sensitive or personal data, compliance with data privacy regulations such as GDPR or CCPA is critical, along with adherence to ethical AI practices that minimize bias.
Each stage in building an AI-powered application adds to a complex structure, with data, algorithms, infrastructure, and cloud computing integrating to form a cohesive system.
With a structured approach, a solid foundation for AI application development is established, providing the technical depth and strategic foresight necessary to navigate large-scale AI projects effectively.
Data Flow in AI Systems: Processing and Continuous Learning for Real-Time Insights
This example illustrates a dataflow approach in which a bulk data unit (e.g., a video sequence) is processed and prepared for use in AI algorithms. While application-dependent, this example follows the processing of a single data unit, such as a video with many frames (where the number of frames depends on the frames-per-second rate). Here, the entire video sequence is used as a dataset, but each frame can be processed independently.
In a system like a face recognition AI, individual frames allow the model to identify a face in each image and track its movement across frames, such as a person walking through a square. By observing frames over time, the AI system can detect patterns, predict next steps, and anticipate behavior based on data from other similar videos. Thus, the model may learn a person’s movement patterns in various scenarios, predicting actions by comparing them with previously learned behaviors.
The diagram would describe a data collection phase, where each video sequence (or data bulk) is gathered and processed through machine learning algorithms. Once processed, outputs such as serialized objects, data marts, or mathematical matrices are stored in a persistence layer. If the data contains events requiring immediate action by an AI model, the system would invoke the necessary AI interfaces, then terminate the current operation.
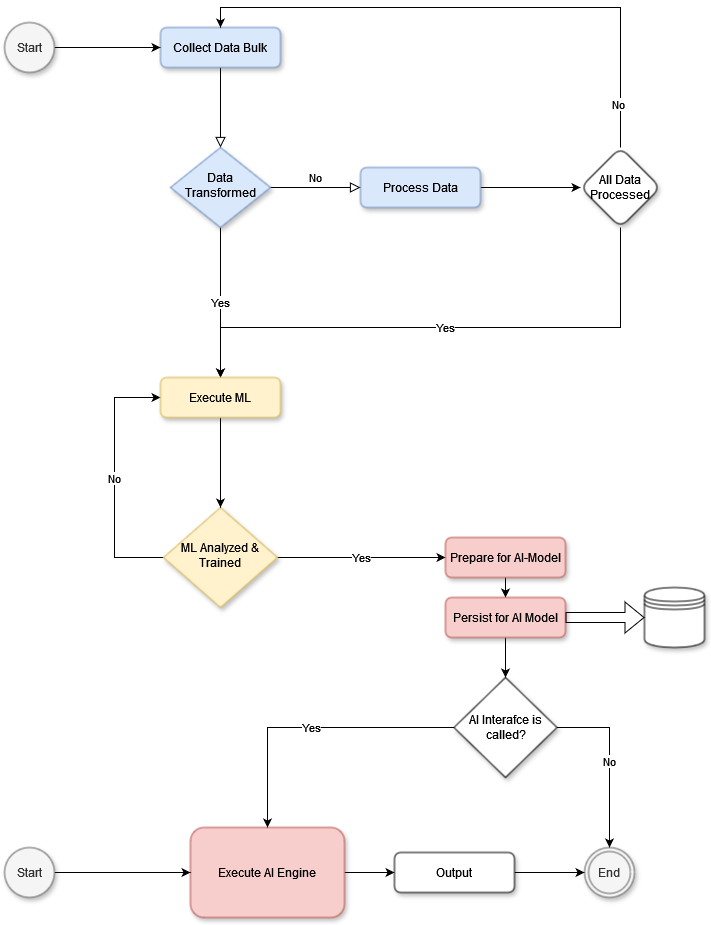
In live ML or AI systems, this workflow becomes more complex. Just as humans continually learn and adapt, AI learning is ongoing, running in parallel with other processes. Multiple specialized threads allow for continuous training and adaptation, so the system remains responsive and relevant as new data is integrated.
In essence, this example emphasizes the importance of data flow and parallel processing in a scalable AI system, balancing immediate responses with the need for continuous learning.
Runtime Environment and Backend Non-Functional Requirements
| Term | Definition |
|---|---|
| AI (Artificial Intelligence) | The simulation of human intelligence in machines that are programmed to think, learn, and solve problems autonomously or semi-autonomously. |
| ML (Machine Learning) | A subset of AI that focuses on training algorithms to recognize patterns in data and make predictions or decisions without explicit programming for each task. |
| Real-Time Processing | The ability of a system to process and respond to data as it is received, providing outputs or results almost instantaneously. |
| Non-Functional Requirements | Characteristics of a system such as performance, scalability, security, and usability, which define how a system operates rather than what it does. |
| Data Marts | Specialized storage structures designed to serve a specific purpose, such as optimizing data for analytics. They typically contain aggregated data for easier and faster access. |
| Data Lake | A storage system that holds large amounts of raw data in its original format until it is needed for analysis. Data lakes support various data types, including structured, semi-structured, and unstructured data. |
| ETL (Extract, Transform, Load) | A data integration process where data is extracted from various sources, transformed into a suitable format, and loaded into a data warehouse or data mart. |
| ISAM (Indexed Sequential Access Method) | A method for data retrieval that allows data to be accessed in a sequence or directly through an index, commonly used in high-performance data systems. |
| Data Pipeline | A set of processes and tools used to transport, transform, and load data from one system to another, enabling real-time or batch data processing. |
| Data Quality Checks | Processes to ensure that data is accurate, consistent, complete, and reliable. Quality checks are crucial for maintaining the integrity of data used in AI systems. |
| TensorFlow & PyTorch | Popular open-source libraries used for building and deploying machine learning and deep learning models. TensorFlow is known for its scalability, while PyTorch is favored for ease of experimentation and flexibility. |
| Cloud-Based AI and ML Platforms | Platforms such as Google AI Platform, AWS SageMaker, and Azure Machine Learning that provide tools for building, training, and deploying machine learning models in the cloud. |
| Distributed Training | A method of training ML models across multiple machines or processing units simultaneously, allowing for faster model development with large datasets. |
| AutoML (Automated Machine Learning) | A suite of tools and methods that automates the ML model-building process, from data pre-processing to model training and tuning. Examples include Google AutoML and H2O.ai. |
| APIs (Application Programming Interfaces) | A set of protocols and tools that allow different software applications to communicate. APIs are essential for exposing machine learning insights and enabling real-time decision-making. |
| Docker | An open-source platform used to develop, package, and deploy applications in lightweight containers, enhancing portability and scalability. |
| TensorFlow Serving & NVIDIA Triton Inference Server | Specialized serving systems that optimize machine learning model deployment, enabling low-latency, high-efficiency predictions for production environments. |
| Logging and Monitoring (Prometheus & Grafana) | Tools used to collect, store, and visualize performance metrics. These tools help track system performance, data drift, error rates, and other key indicators to ensure stability and efficiency. |
| Horizontal Scaling | Adding more machines to increase a system's processing power, allowing it to handle more workload without overloading a single machine. |
| Vertical Scaling | Increasing the resources (e.g., CPU, memory) of a single machine to enhance its performance. This approach is often used when data volumes are manageable by one machine with sufficient power. |
| Data Privacy Regulations (GDPR & CCPA) | Laws governing the collection, storage, and use of personal data to protect user privacy. Compliance with these regulations is essential in AI applications, especially those handling sensitive information. |

- Aktuelle Seite:
-
Startseite

-
Informationssysteme
-
Die Bedeutung der Bewertung von Berater- und Entwicklerprofilen
- Uncategorised